Challenge 02
Due: 2025-04-10 at the start of class
Download Starter Files Submit on GradescopeWe will review revisions of challenges on a rolling basis, and if you submit early you may have a chance to go through multiple revision cycles. As students often submit work that is not finalized to gradescope, we ask that you fill out this form to indicate that your submission is ready to be regraded.
Objectives
- Demonstrate your ability to design and write a function on your own
- Demonstrate your ability to use repetition in code
- Demonstrate your ability to effectively use data structures
Challenges
Challenges are your moment to demonstrate your ability to apply the concepts from the class independently. We may provide a framework that allows us to test your code and a description of the problem to be solved. The design of that solution is left up to you. We will not tell you how many functions to write, their names or what their parameters should be, nor will we dictate any implementation details beyond the requirements placed on what data you wll be given and what form we expect any data to be output. The only requirement is that your submission be entirely your own work.
Requirements
Challenges will only be marked Satisfactory, Incomplete or Unassessable.
To be marked Satisfactory,
- your code must meet the functional requirements (as embodied by the tests of Gradescope)
- your code must pass the style tests
- any function you write must have well formed docstrings that describe the purpose of the function, the name and type of each parameter and the return value
- your design should demonstrate good choices with respect to choices of abstraction and implementation (i.e., what to create as a function, how to handle repetition, how to break up conditions, etc…)
There are many ways to demonstrate good choices. At the largest scale, we will be looking at how you use abstraction. Your functions should just do one thing, and that thing should make sense as a part of the problem you are solving. If you can’t describe what your function does in a simple sentence, it is probably too complex. On a small scale, good choices illustrate your grasp of how your tools work. For example, we might look at unnecessary type conversions (like converting a string literal to a string, e.g., str("already a string")).
Submissions that are marked Incomplete will be eligible to be revised after feedback is returned. New work, or work that is Unassessable when the first submission period closes will not be accepted for revisions.
The Problem
For your second challenge, we would like you to write a program can generate random text in the style of some other document. To give you maximum flexibility, your program will read in a configuration file then write the results back out to a different file (please read all of this page before starting to implement this – we have a very specific configuration format).
Markov Chains
At the heart of this is something called a Markov Chain. In simplistic terms, the Markov Chain is a tool for determining a set of likely next events given a sequence of prior events. It is frequently used for predictive typing (if you send message on a smart phone, you have probably seen this in action). By observing a lot of messages, we can build up a statistical model that tells us what is the most likely next word given the words that have already been typed. As a really simple example, if someone asks you a question, the most common responses are “yes”, “no”, or “ok”, so those are the options that are presented to you. I just tried “I want” on my phone, and it responded with “to”, “a”, and “you”. Behind the scenes, there are probabilities attached to all of the possible next words. This is implemented through a language model1 and the model that you’ll implement is a simpler implementation of a language model.
If you consider each word to be an “event”, each event causes a transition in the chain, with a new set of possible next steps. The longer the chain we consider, the more accurate the prediction.
We are going to generate random text based off this theory. We will start with a text document which will serve as our model of language. We will read the document in and use it to build our Markov Chain. Generating random text then involves picking some random start word and then picking one of the possible next words at random (though taking the probability into account). Then we will repeat to find the most likely word to come after that, etc… Some of you may have already played this game on your phone: you type a random word, then pick one of the options it presents at random, and then repeat. You will get random, probably nonsensical, but plausible messages. Here is one: ‘Computer science is a very important field of study and it can help us to learn about how computers work’. I started that by typing ‘Computer’, and then semi-randomly picking one of the three options presented to me after each word (I biased slightly towards making sense).
Details on Generating Text
Imagine you are trying to generate text in the style of this text (included in the starter code):
Imagine there’s no heaven
It’s easy if you try
No hell below us
Above us only sky
Imagine all the people
Living for today…
Imagine there’s no countries
It isn’t hard to do
Nothing to kill or die for
And no religion too
Imagine all the people
Living life in peace…
We can write a Markov model with any order; this is the number of prior words that are considered when generating a new word. In this example, we will look at prefixes of length 2 (order == 2). So, one prefix would be “Imagine there’s”. 100% of the time, it is followed by the word “no”. However, the prefix “there’s no” is followed by “heaven” 50% of the time and “countries” the other 50% of the time. “people Living” is followed by “for” 50% of the time and “life” 50% of the time. The rest of the prefixes all have one word that always follows them 100% of the time.
The best way to approach this process is to assume that we have one long list of words. Starting from the beginning, we look at the first order words. This is the first prefix. The next word is then a suffix that we want to associate with this prefix in our collection. Once we’ve stored that word, we slide our “window” forward one word to make a new prefix, and repeat the process.
Here is a picture that illustrates the process with ah order of 2. I used numbers to make it easier to draw and read, but your actual model will use words.
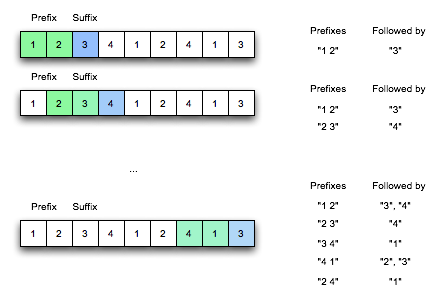
The principle of how we will generate words is that we can generate a chain of words following our Markov model of the text document. Given a prefix, we add one of the suffixes associated with this prefix randomly, proportionally to how frequently that word appears in the text. The “chain” part comes in because we will again slide forward, this time in the output text. Sliding forward by one word gives us a new prefix, ending with the most recently added word. We randomly pick one of the suffixes associated with this new prefix, add it to the output and so on.
An example
Here is a simple example of a random walk using a second-order Markov chain. To make things simpler, I am just going to use letters instead of full words. Here is the input text:
A B C D B C E A B E C D A B C A
From this we find:
A Bis followed byC\(\frac{2}{3}\) of the time andE\(\frac{1}{3}\) of the timeB Cis followed byA\(\frac{1}{3}\) of the time,D\(\frac{1}{3}\) of the time, andE\(\frac{1}{3}\) of the timeB Eis followed byC100% of the timeC Dis followed byA\(\frac{1}{2}\) of the time andB\(\frac{1}{2}\) of the timeC Eis followed byA100% of the timeD Ais followed byB100% of the timeD Bis followed byC100% of the timeE Ais followed byB100% of the timeE Cis followed byD100% of the time
Now we can build some random text:
pick random prefix, text now: C D
pick suffix of last two characters: C D B
pick suffix of last two characters (no choice): C D B C
pick suffix of last two characters: C D B C E
pick suffix of last two characters (no choice): C D B C E A
pick suffix of last two characters (no choice): C D B C E A B
pick suffix of last two characters: C D B C E A B C
pick suffix of last two characters: C D B C E A B C A
no prefix, pick random prefix: C D B C E A B C A C D
pick suffix of last two characters: C D B C E A B C A C D B
pick suffix of last two characters (no choice): C D B C E A B C A C D B C
pick suffix of last two characters: C D B C E A B C A C D B C D
(and so on…)
You’ll note that when we run into a prefix that was not in the input data, we choose one at random.
Details
We want to give you the maximum amount of flexibility with this challenge while still retaining the ability to provide you with on demand feedback with the autograder, so we have had to give you a little bit of a framework to support these two competing demands.
main()
In the starter code (challenge02.py), you will see the following code:
import task_handler
def main():
"""
This is the "main" function that drives your program. This is the function we will call when we want to run your code.
"""
handler = task_handler.get_handler()In non-challenge assignments, we have written individual functions and tested them directly. In this challenge, like the last one, you will be writing a program that carries out multiple operations. Programs typically have a function called main that serves as the entry point – where the first instruction to run is found. This is the function we will call to run your code.
A good solution to this challenge is unlikely to put all of its code in main() (very unlikely…). You can, of course, test any function you write independently of main, but bear in mind that we won’t know what your functions are, so we will only run main.
Configurations
Like Challenge 1, we’ve provided you with some code that helps to handle file operations as we have not yet talked about how to handle them. However, the input that you’ll need to process is a bit more complicated in this case. Take a look at configuration.json, which shows the input you’ll process in your code.
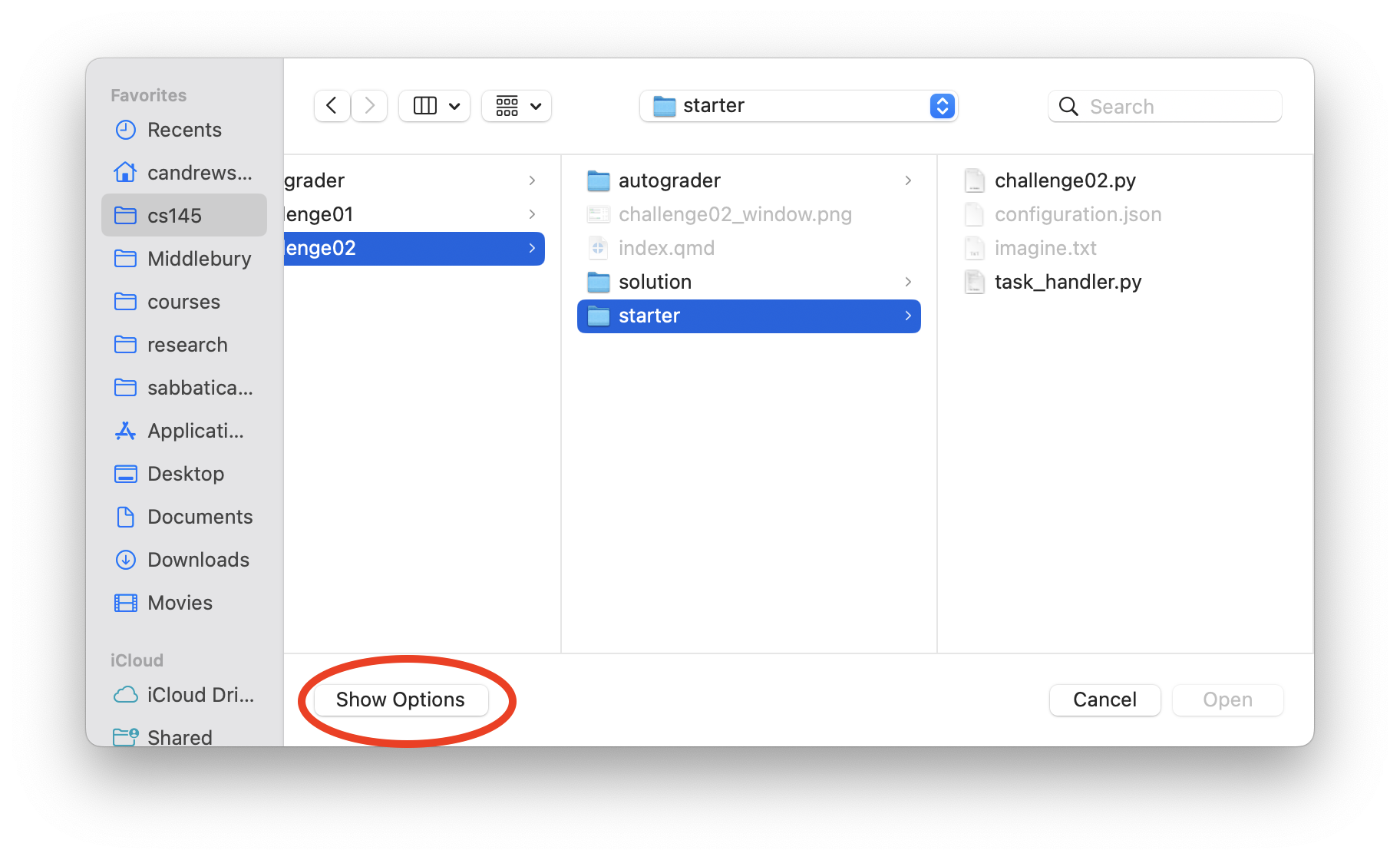
.json and .txt files in Thonny
In Thonny, by default you will only be able to open Python files. To open other file types, open the open menu as you usually would, and then click “show options” (circled in red in the screenshot below):
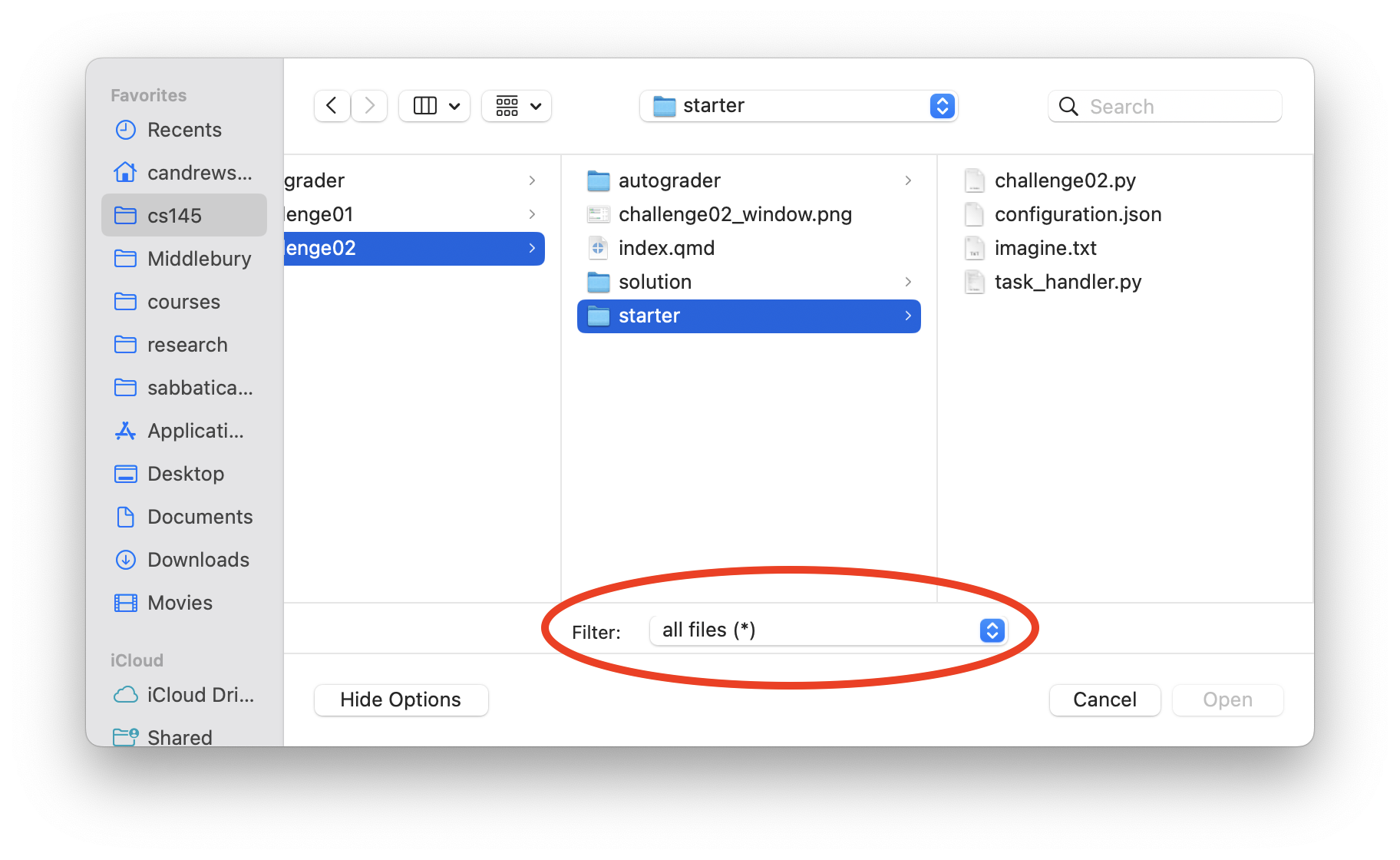
Then, you’ll see a dropdown (circled below), from which you should select “all files (*)“.
configuration.json should look kind of like a dictionary, containing the following:
input_filename
This specifies the file containing the input text. We’ve provided you with imagine.txt, but we hope that you’ll get creative and experiment with other input files!
This is a great moment to visit Project Gutenberg, which hosts free ebooks as plain text files. The text generator is much better when it has a lot of source material. If you generate anything fun, post it on Campuswire! Just replace imagine.txt with the name of the file you downloaded to change your input data.
order
This is the order for your markov model. We will test your code with multiple values, so try changing this up!
tasks
This is a list specifying the tasks you must complete in your program. A task includes "generate_n_words", which is the number of words to generate before stopping, and (optionally) "prefix", which is the first prefix that you should use when generating text. If "prefix" is not specified, you should choose a random prefix from those you saw in the input text.
When "prefix" is not specified, you can assume that "generate_n_words" is greater than or equal to "order". The random generated prefix counts towards your n words that you should generate.
output_filename
For each task you process, you should write the output to the file specified here. The output string should include the prefix and the generated text, with words separated by a single space. You won’t need to write to the file directly; we’ll describe how to do so with the task handler below!
The task handler
We’ve provided task_handler.py, which handles reading the configuration and input files and writing data to the output file.
The module has one function: get_handler(), which I’ve already provided for you. This returns the handler with which your code will interact.
The handler reads in the configuration and the input file. It has three methods:
handler.get_configuration()- this returns a dictionary with all of your configuration information. It will have keys"input_text","order", and"tasks". The dictionary differs fromconfiguration.jsonin that the output filename is not included and the input file is read and stored in"input_text".handler.write_output(output)- this has a single parameter (output). The value of the parameter will be written out to the output file
Using these two functions and your own code, you are expected to create a model based on the text in the input file and write out (in order) the text that you generate for each task that is specified.
You should not need to look in task_handler.py, and you certainly should not change anything in the file. However, you are welcome to poke through the code. There are a number of things in there that you will be unfamiliar with, but you will at least be introduced to most of them by the end of the semester.
Randomness
The random module contains lots of functions that could help you with this task! Please use one of the following functions when you need randomness in your code:
random.randintrandom.randrangerandom.choicerandom.choices
You must use them in a natural way for your code to be considered satisfactory. For instance, don’t call random.choice(range(0, 10)) when you could call random.randrange(0, 10). You also must remove any superfluous calls to random functions used for testing!
Strings to words and vice versa
To split strings into a list of words based on whitespace, you can use the .split method. For the sake of testing, we expect that for lowercase alphabetic characters, your method of splitting strings will be identical to the .split method. However, feel free to be creative about how you choose to process other characters such as punctuation, uppercase characters, etc.! We will test that your code runs with these characters as input, but will test for correctness using only strings of lowercase alphabetic characters separated by whitespace to allow for creativity.
To take a list of strings from a list lst and convert it into a single string separated by spaces, you can use the .join method, e.g., " ".join(lst).
The syntax on this is admittedly weird. We are calling the function on the string we want to use as the separator. This was written this way because it was decided this function had more to do with strings than lists (because this doesn’t work for anything other than lists of strings). That doesn’t make it look less weird. After a while you will get used to it.
Submission
As usual, you are encouraged to submit early and often to test your work against the autograder. The only file that you need to submit is challenge02.py (and any other files you may have written as part of your solution). You do not need to submit input or output files, nor do we need task_handler.py.
Footnotes
Likely a large complex model that is similar to ChatGPT↩︎