More on Evaluating Classifiers
Spring 2026
What is the task that the classifier is supposed to perform?
Researchers analyzed aspects of a person’s life story between 2008 and 2016, with the model seeking patterns in the data. Then, they used the algorithm to determine whether someone had died by 2020. The Life2vec model made predictions with 78% accuracy.
- Media writeup of Savicsens et al, 2024. “Using Sequences of Life-Events to Predict Human Lives.” Nature Computational Science 4 (1): 43–56.
…They used the algorithm to determine whether someone had died [between 2016 and 2020]. The Life2vec model made predictions with 78% accuracy.
What do you wonder?
From the authors:
Because our cohort is very young, almost everyone survives (more than 95%).
This means that if we created an algorithm that always predicted “survive”, it would get a very high accuracy (over 95%).
To address the issue, we balance the dataset, equivalent of 50,000 with survive outcome and 50,000 with death outcome. In this balanced dataset a random guess would get 50% accuracy.
When we run our algorithm on that balanced dataset, we get 78.8% accuracy.
Task: determine whether a given high school student is at risk of dropping out of school in the future.
Is the task that the classifier is intended to perform actually possible?
We study, for the first time, automated inference on criminality based solely on still face images, which is free of any biases of subjective judgments of human observers…
All four classifiers perform consistently well and empirically establish the validity of automated face-induced inference on criminality, despite the historical controversy surrounding this line of enquiry.

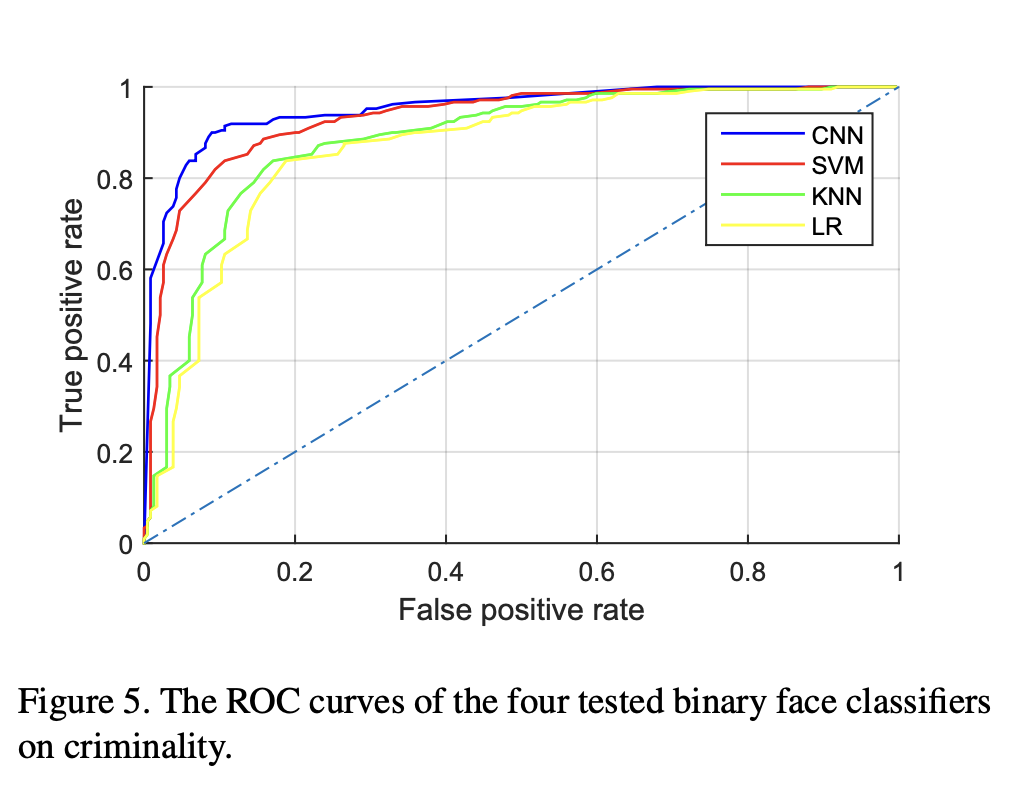
Wu + Zhang, 2016: “Automated Inference on Criminality using Face Images,” arXiv preprint
What do you notice? What do you wonder?
Always ask about the data…
Subset \(S_c\) contains ID photos of 730 criminals… published as wanted suspects by the ministry of public security of China and by the departments of public security for the provinces of Guangdong, Jiangsu, Liaoning, etc.; the others are provided by a city police department …
Subset \(S_n\) contains ID photos of 1,126 non-criminals that are acquired from Internet using the web spider tool; …including waiters, construction workers, taxi and truck drivers, real estate agents, doctors, lawyers and professors….
Informative features, according to the researchers
